About the Author: Alexander Wu (geekan) is the creator of MetaGPT, a startup CEO, and a seasoned software engineer. He authored the first version of MetaGPT’s codebase and brings 18 years of programming expertise to the project. At the peak of his technical versatility, Wu worked with 21 programming languages within a year.
2. Content
2.1 Motivation
On November 30, 2022, while discussing the recent release of ChatGPT with fellow CEOs and CTOs, I asserted that “natural language programming would soon become a reality.” Days later, I scoured GitHub for libraries dedicated to natural language programming or LLM scaffolding that could serve as a foundation for this concept. Initially, I assumed finding such a library would be straightforward—indeed, someone else had conceived this idea.
My reasoning was simple: code is deterministic while natural language is probabilistic. The conversion process seemed to be merely a translation exercise. Although this translation appeared sophisticated by current standards, it felt within reach. Of course, this translation might require multiple steps, similar to Standard Operating Procedures in human organizations, where different professional roles contribute to a complete process.
I believed this would be a quick consensus among developers. However, after examining several leading open-source repositories, I couldn’t find a single line of code aligned with my vision. This led me to question my judgment, but being persistent by nature, I remained convinced that natural language programming was feasible.
2.2 Reading Open-Source Repositories
After examining approximately 70 open-source libraries for over four months, I still hadn’t found what I was looking for. LangChain was a repository I had initially hesitated to tackle due to its intimidating codebase size. Having exhausted most other options without success, I finally took a deep breath and decided to confront LangChain.
I use a custom script with grep and various bash commands to measure library complexity. If my memory serves correctly, the analysis revealed that LangChain contained 95,183 lines of code, 2,826 functions, and 655 classes (for comparison: AutoGPT had 12,517 lines, JARVIS had 1,886 lines, and GPTeam had approximately 5,000 lines). What mainly frustrated me was LangChain’s excessive use of syntactic sugar in classes, offering three or four different approaches to solving the same problem, all yielding identical results.
This reminded me of Scala, a language with a notoriously enigmatic learning curve. My biggest frustration with Scala was its abundance of syntactic sugar, often implemented through various symbols. When reading others’ code that utilized these symbols, I would become completely disoriented, uncertain where even to look up their actual meanings or whether symbols like ”>>:” represented one operator or several.
For example, 1 >>: List(2,3) produces List(1,2,3)
Python’s philosophy advocates for a single, straightforward way to accomplish tasks—“There should be one, and preferably only one, obvious way to do it.” While Python’s vast ecosystem of libraries has made it increasingly difficult to adhere to this principle, I believe that steering a library toward Scala-like complexity within the Python ecosystem is counterproductive.
I invested considerable time forcing myself through most of LangChain’s logic, meticulously deconstructing its components layer by layer until I finally managed to map out its core workflow—a painstaking but necessary process.
Along the way, I created a comprehensive document exceeding 10,000 words. During my analysis, I initially grew excited upon discovering what appeared to be numerous algorithm implementations, thinking I had found what I was seeking. However, as I delved deeper, something felt off—beneath layers of abstraction, the core logic was elementary and not what I had envisioned.
What rationale could justify the utilization of over 90,000 lines of code for such seemingly straightforward logic? I had anticipated that a few hundred lines may be sufficient. Upon reflecting on my prior experiences, I maintain that my programming skills have remained relevant, notwithstanding my focus on company management for several years following a decade of coding. Consequently, I took the initiative to develop my own solution.
Still, hesitation lingered. To bolster my confidence, I first wrote over 30 analytical documents examining different open-source libraries. Voyager and Generative Agents impressed me most among the open-source projects I studied—their code architecture and conceptual approaches were genuinely innovative. Being completely honest, even looking ahead to 2025, I still consider their approaches and implementation advanced.
Voyager achieved an exceptionally high level of abstraction with a clean architecture that felt intuitively correct, as if revealing a fundamental truth. It implemented sophisticated designs based on reinforcement learning frameworks that, at first glance, I doubted my ability to conceptualize independently. The elegance and clarity of its codebase were truly remarkable.
Upon its release, Generative Agents implemented multi-layered memory through summarization techniques that effectively simulated human memory mechanisms. Their masterful use of emojis in demonstrations elevated the presentation to an art form, setting a standard of communication excellence I found challenging to imagine surpassing.
However, most open-source libraries failed to reach the caliber of Voyager and Generative Agents. Like LangChain's 90,000+ lines of predominantly superfluous abstraction, many projects suffered from inefficient implementation. After completing my comprehensive analysis of these repositories, I concluded that the average code quality fell short of my own standards, which somewhat bolstered my confidence. However, I remained uncertain about optimal design principles.
2.3 Reflection and Validation
During my analysis, I noticed several libraries like AutoGPT and GPT-Engineer beginning to explore this space, though their approaches differed significantly from my vision. This divergence likely stemmed from my experience as a software company CEO. Years in this role taught me that producing effective code requires a comprehensive set of standard operating procedures. Implementing these SOPs with human teams proved challenging. Simply convincing people to follow guidelines or write essential documentation often requires substantial persuasion.
This experience clarified why software companies need specialized roles: product managers, architects, engineers, QA specialists, and project managers. I understood how these positions create optimal organizational structures. Throughout my management career, I developed numerous SOPs covering thinking methodologies, communication protocols, task execution, research techniques, documentation standards, decision frameworks, meeting procedures, and pathways to becoming a 10x engineer. I even created meta-SOPs to develop new SOPs—all in pursuit of building an exceptional organization.
I reasoned that LLMs, as compressions of world knowledge, should naturally adapt to established operational paradigms. Despite considering myself reasonably intelligent, I spent years distilling these SOPs from practical experience. The internet lacks systematic documentation of these practices, with only fragments scattered across various publications. LLMs likely wouldn’t possess this knowledge inherently.
To test this theory, I used GPT-4 to validate my approach of transplanting real-world SOPs into the coding domain to enhance LLM performance. Humans required centuries to refine these operational frameworks, and I doubted LLMs could intuitively develop them, mainly because they primarily express the statistical average of internet content.
I tested this approach by asking GPT-4 to develop product requirements and architectural designs based on my concepts. After careful selection and multiple iterations, several designs appeared viable for practical implementation. I shared one recommendation system design with a group containing some of the industry’s top recommendation engineers. They acknowledged the impressive completeness of these designs, with many admitting that the design quality exceeded their own capabilities. Some even expressed concerns about their future job security.
This validation convinced me of the approach’s viability. At that moment, I believed I was closer to the truth than others in this space. I asked myself: if I’m confident in this direction, why not start building?
So, I created a new project in PyCharm called “meta_programming”—named for its purpose of “using programs to generate programs.”
2.4 The Design and Implementation of MetaGPT
GPT-4 became an invaluable partner in my journey. Finally, I had a collaborator who could exchange ideas around the clock without mental fatigue. Through extensive conversations with GPT-4, I refined the architecture for MetaGPT. Here’s a small excerpt from those discussions:
This constitutes a comprehensive system integration project involving multiple abstract concepts and data structures. After formalizing all components, the integration process follows this technical blueprint:
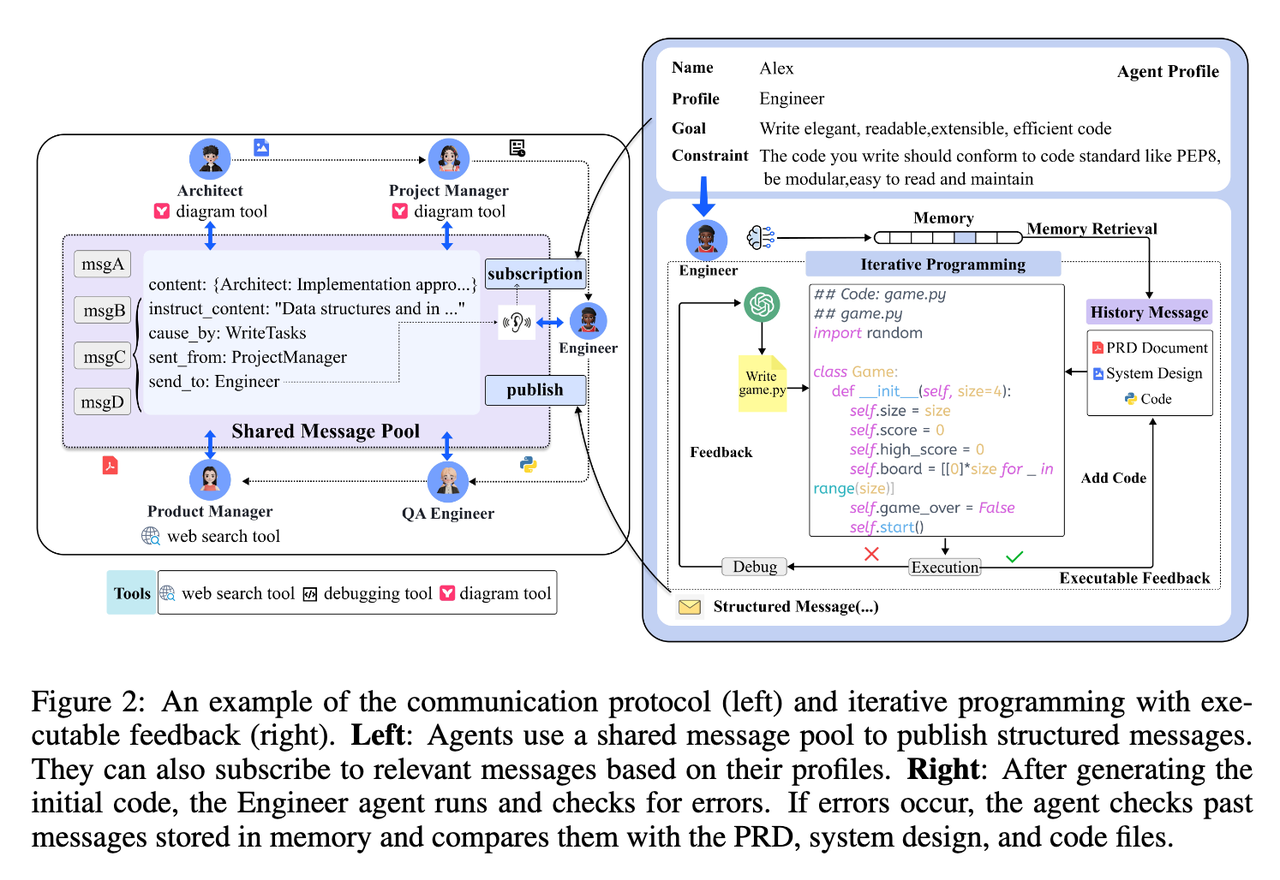
Define the objects for each Role. Each Role should possess a unique name and be associated with input data such as profile, goal, and constraints. Additionally, each Role should have a set of related Action that delineates its specific operations.
Create a Manager object to orchestrate the execution of these Role. The Manager should include a method to add a new Role to the system. Additionally, Manager should feature a method enabling individual Role to determine and execute specific Action based on their current state.
Employ an LLM object to furnish the execution environment for each Role’s Action. All Role should collectively utilize the same LLM object, except in specific scenarios where a distinct LLM instance is necessary.
For each Action, clearly define both the input and output data. The input data must be in a format processable by theLLM, such as strings, or types that can be readily converted to strings. The output data should represent the result generated upon the completion of the Action.
Tool objects may be employed by either Role or Action to perform specific tasks, such as facilitating interactions with external systems.
The process may unfold in roughly the following manner:
The Manager adds each Role to the system.
For each Role, the Manager checks its status and calls the appropriate Action based on that status.
The Action is executed using the LLM and may utilize services provided by the Tool.
Upon completion, the Action returns the result to the Role, which updates its state.
The Manager rechecks the status of each Role and repeats steps 2–4.
This is only a very preliminary process design; the actual implementation may be adjusted according to the specific requirements. Moreover, the concrete implementation of each abstract concept (Role, Action, LLM, and Tool) must also be designed and optimized based on the actual situation.
I leaned toward introducing an environment concept and implementing Role autonomy. Roles could sense other roles within the environment in this design and publish information. During each cycle, the system would first check for messages requiring attention. The Manager would then determine which Role should handle each message and distribute tasks accordingly.
Incorporating the concept of an environment and the functionality to publish information indeed boosts the system’s flexibility and adaptability. This design paradigm aligns more closely with the nature of multi-agent systems, where each agent can independently sense and respond to its environment. With this in mind, we can refine the earlier process as follows:
Create an Environment class that encompasses all Role and the Manager. This class should also feature a message queue for receiving and dispatching messages.
When a Role’s state changes, it can publish a message to the Environment, including details about the changed state and relevant information regarding the change.
The Manager periodically inspects the Environment’s message queue. For each message, the Manager identifies which Role or Roles should process it and subsequently invokes the appropriate Action.
The Action is executed using the LLM and may leverage services provided by the Tool.
Upon completion, the Action returns the result to the Role, which updates its state and may publish a new message to the Environment.
The Manager re-inspects the Environment’s message queue and repeats steps 3 to 5.
This design approach ensures the system’s autonomy and adaptability. Different Role can dynamically respond to messages within the environment, while the Manager orchestrates the activities of these Role.
Adding an environmental concept and message publishing capability would indeed enhance the system’s flexibility and adaptability. This design better aligns with multi-agent system principles, where agents independently perceive the environment and respond accordingly. Based on this insight, we could refine our previous workflow:
I wrote approximately 4,000 lines of code and got the system working, but still considered it immature. Despite its ability to solve specific problems, the success rate wasn’t high enough to satisfy me. I planned to optimize it further before release, though I lacked clear improvement strategies.
When Lilian Weng published her blog about AI agents on June 23rd, plans changed. Several friends forwarded it to me, asking about my project’s status. I reconsidered: perhaps users would accept the system despite its imperfections? After all, it might have been the most advanced work in this space then.
Before publishing, we discussed naming options. While I was fond of “meta-programming,” others found it too lengthy. I asked GPT-4 to generate and evaluate over 40 potential names. Its highest-rated suggestion was “MetaGPT,” which I ultimately adopted after careful consideration.
I published MetaGPT at https://github.com/geekan/MetaGPT/ on June 30, 2023. In the month of August, it achieved the distinction of ranking #1 on GitHub Trending on 17 separate occasions.
After release, our community expanded rapidly. Some members suggested writing a research paper, a welcome proposal since I lacked the time to do so myself. This led to a community-sourced paper (https://arxiv.org/abs/2308.00352). I was pleased with the quality and sincerely appreciated the community members who trusted my code.
Title of paper and authorsAs can be seen, our implementation is close to the GPT-4 design
2.5 Do it the Hard Way
I firmly believe meta-programming requires substantial scientific research. From 2023 to 2025, I maintained a daily habit of reading arXiv papers, scanning titles and abstracts of approximately 100,000+ papers. From these, I cataloged 2,100 and highlighted fewer than 300 as particularly significant.
These papers primarily focused on agent technology and were filtered through my personal research interests. I assembled an academic team to summarize these papers and develop novel perspectives collaboratively. If we consider the human brain to consist of 22 modules, current LLMs only correspond to about 7 of these modules. The remaining 15 modules have yet to be implemented. These unimplemented modules primarily relate to embodiment and agency.
We plan to publish our comprehensive paper in March. It traces the history of AI agents, establishes formal definitions, and offers numerous insights. I strongly recommend reading it, as we’ve identified significant gaps in current research. For example, human rewards are driven by internal hormonal systems, while agent reward mechanisms remain rudimentary. Improved implementations could yield fascinating emergent behaviors.
Over the past two years, I’ve contributed to approximately 10 research papers covering agent workflows, automated experimental systems, and optimal context utilization. Looking ahead, we’ll establish a new open-source organization to engage more contributors in this work. Clearly, with the help of agents, we have the potential to evolve into a more advanced civilization.
2.6 A Short Story-Metaprogramming
Meta-programming reminds me of C language Macros. Macros allow code to rapidly expand into new code, implementing features that would be difficult to express in C. They can sometimes save dozens of times the byte count. Both meta-programming and Macros solve the same fundamental problem: code generation.
Years ago, QEMU implemented a class system using C Macros, which I found incredibly impressive. This demonstrated the power of macros, though debugging such code proved challenging—everyone used them with extreme caution.
I recall a former colleague who wrote macros that generated substantial amounts of repetitive code. I specifically sought his guidance on his technique. I sometimes wondered if company evaluations might favor him since his code volume statistics would significantly exceed others. His code was aesthetically pleasing, but it was just challenging to modify.
I’ve written many macros myself and understand their intricacies. Shortly after graduation, I contributed to the OpenVSwitch open source project as a new engineer. The project employed numerous coding techniques, and through it, I learned to generate code using macros. Here’s an example:
The OFPACT definitions demonstrate how macros can expand into asserts, enums, and structs, enabling efficient code production with minimal syntax. Similar macro patterns appear frequently in C open source projects and the kernel. However, they share several fundamental challenges:
First, debugging becomes extremely difficult. Minor issues can cause system-wide failures that are hard to detect, and using GDB with different optimization levels can create frustrating debugging experiences.
Second, they demand extensive mental computation. Authors must fully understand their actions, mentally trace execution paths, anticipate exceptions, and identify potential failure scenarios. Even determining the macro compilation order can be a disaster if mismanaged.
Third, they impose a substantial memory burden. These structures exist outside standard textbook patterns, requiring developers to memorize implementation details or maintain obvious documentation. Otherwise, revisiting the code even days later often necessitates complete reanalysis.
Although the problems with macros are obvious, they remain incredibly appealing because, once properly expressed, they can save substantial amounts of code.
Creating macros feels like inventing your own language - “Who could resist such temptation?
However, we must remember that languages are communication tools. Programming languages specifically help us communicate with machines. Our fundamental problem is “how to communicate with machines efficiently.” Setting aside all their drawbacks, macros might achieve a 10x leverage, where one byte I write generates ten bytes of code.
2.7 Conclusion
I’m delighted that MetaGPT has inspired numerous teams and sparked innovation across the global tech landscape. Various multi-agent communities have developed fascinating connections with our work.
In the time it takes me to write a single byte, MGX (MetaGPT X) can generate thousands, achieving efficiency two orders of magnitude beyond macros. This technology translates ambiguous natural language quickly into precise machine code. Today, there are 28.7 million engineers worldwide. As natural language programming dramatically lowers entry barriers within a year or two, this number could rapidly expand to hundreds of millions. However, just as TikTok didn’t replace Hollywood, natural language programming won’t eliminate software engineering. The fundamental structures of software engineering will persist, though both the tools and their users will evolve.
But could this become the final programming language? Just as DeepSeek R1 can already write CUDA code superior to human efforts, perhaps in a few years, we’ll all learn to use natural language programming—potentially the last programming language humanity will ever need to invent.